附2:stack overflow的bosun架构
(本文翻译自bosun项目组长Kyle Brandt在其个人博客上写的一篇文章,原文地址:http://kbrandt.com/post/bosun_arch)
bosun是Stack Overflow网站关于监控的基础设施中重要的一环,在类似于Bosun的Slack聊天室的讨论社区中,我们经常被问及关于如何描绘在我们的架构中bosun是如何运作的。本篇文章就是一份详细的解答,关于围绕bosun的预警架构。我们的架构方式并不是唯一使用bosun的方法,当然也不是最优的方法,但是我们的架构对于我们自己而言是当前环境下地最优解。
组件
围绕bosun,我们使用了大量的其他组件,但是他们中得每一个在我们基础架构中有独特的作用,下面的表格详细的列出了它们:
| 组件 | 作用 | 描述 |
|---|---|---|
| Bosun | 预警系统 | 1、评估OpenTSDB、Graphite、Elastic、InfluxDB2等数据库时序的表达式语言2、表现力强大的通知模板,包括HTML、图、表格、内嵌CSS样式3、强大的web接口,支持查看预警、编写表达式和图、创建预警和模板、基于历史信息测试预警4、存储指标数据和标签的字符串数据(例子:机器IP信息、序列号等) |
| scollector | 采集代理 | 1、同时支持windows和linux,通过API投递系统和应用信息,也能支持对SNMP、ICMP的支持2、不需要进行配置,它就会会监控它自己发现的所有应用(包括IIS、Redis、Elastic等)。只需要少量的投递参数配置。 |
| BosunReporter.NET | APP指标收集 | 发送应用的指标数据到bosun系统 |
| OpenTSDB | 时间序列数据库 | 1、收集时间序列数据并将其存储在Hbase中2、时间序列数据是经过标签化的,因此它是一个多维度的时间序列数据库 |
| Opserver | 监控仪表 | 1、从SolarWinds或bosun拉取数据2、同时也包含了针对Redis、SQL Server、HAProxy和Elastic独立而又深入地预警和控制 |
| Grafana | 用户仪表 | 通过使用bosun插件来通过bosun的表达式创建图表 |
| TPS | 解析Web日志 | 发送原始日志并使其结构化、统计化成时间序列数据到bosun系统中去 |
| tsdbrelay | 1、转发时序数据和元数据 | 在多个数据中心交叉备份时间序列数据和元数据2、创建OpenTSDB指标以获得更快地查询速度 |
| HBase | OpenTsdb存储服务 | 1、HDFS(分布式文件系统、MapReduce计算框架、Zookeeper集群管理)2、Hbase,谷歌BigTable项目在Hadoop中得实现3、Cloudera Manager,用来管理Hbase |
| HAProxy | 负载均衡设施 | 我们使用它来作为Bosun、OpenTSDB守护进程、Tsdbrelay的对外代理 |
| Redis | 内存存储 | 可以选择的bosun使用它来作为存放状态、元数据、标准索引等信息,如果Redis没有被使用,那么使用go实现的内建的数据库LedisDB将会被使用到 |
| Elastic | 文档搜索 | 我们使用它来保存系统日志,能够通过bosun表达式来查询,Grafana的Bosun插件可以很好地被用来查询并绘制这些日志的图表。 |
指标和查询流
通过多种渠道来收集指标:
- 我们自己控制的应用计算各项指标并将其发送给bosun,C#程序使用BosunReporter.NET来,go程序使用go的收集程序。
- scollector收集各项OS的指标以及它自发现的应用指标
- 网络设备和其他设备无法运行scolletor,所以数据首先要被投递到第三方的机器上,我们指定两台机器运行scollector并且启用其上的投递模式,它们通过SNMP(网络设备)、ICMP的ping消息来收集数据,能够通过插件的方式来扩充收集方式。
不管数据是如何收集到得,它不会被直接的发送到bosun上去,它们首先会被发送到tsdbrelays,这其中有两个目的:
- 转发数据到两个bosun系统上(未来可以支持更多个)
- 反序列化某一类型的数据
实际上数据也不是直接被发送到tsdbrelay上得,我们使用HAProxy来作为tsdbrelay的负载均衡前端,这样我们就可以实现水平的扩展。
因为同样地原因我们在bosun的前端也部署了HAProxy,一旦一个bosun系统进入只读模式,此时它的数据表现会与第二个bosun系统非常不一致,这时候我们就可以同步的切换到第二个bosun上来代替只读的这个。
OpenTSDB的性能在所有的写请求都指向一个节点会会有较大的提升,我们的HAProxy使得我们所有的写请求都能够汇聚到一个OpenTSDB的节点上去。
很多不同的系统会查询时间序列数据库,我们把这些叫做查询流:
- Grafana:通过API
/api/expr使用bosun的表达式来查询OpenTSDB,它也能够直接查询Elastic,与Grafana->Bosun->Elastic这样的查询方式具有相同的效用。 - Opserver:可以直接查询OpenTSD,也能查询bosun的
/api/host接口 - Bosun:当执行警报的过程中,或者是用户通过UI界面进行交互,它能够查询OpenTSDB和Elastic(当有使用这些数据库时)。

OpenTSDB和Hbase
在我们纽约的主数据中心,我们拥有两个Hbase集群,其中一个集群含有三个节点,分别是 NY-TSDB0{1,2,3},另一个集群是单节点模式,运行在NY-BOSUN01机器上,单节点模式集群的目的是备份(关于我们如何备份请参看下面的章节)。
在我们的第二数据中心(名叫"CO")上,我们也拥有一个三节点的Hbase集群,本集群是NY-TSDB集群的镜像集群。这两个Hbase集群并没有通过数据中心之间的连接来复制,而是通过tsdbrelay在转发数据包得时候分别发送一份到这两个集群中。
我们在这两个主Hbase集群中HDFS服务使用的复制因子是3,从Hbase集群只有一台机器,因此就没有HDFS的复制。 我们使用CDH的管理工具来管理我们的opentsdb集群,我们发现Hbase是一套非常稳定的分布式数据库,但是是对于偶发的不清楚来源的请求要做出响应是困难的。
我们使用CDH的管理工具来管理我们的opentsdb集群,我们发现Hbase是一套非常稳定的分布式数据库,但是是对于偶发的不清楚来源的请求要做出响应是困难的。
数据量
- 每个集群每天产生37亿条数据(43000条每秒)
- HDFS每天增长8GB无复制数据(复制后为24GB)
- 当前带有复制的数据总量为7TB
OpenTSDB附加与压缩
在我们2015年刚开始使用Hbase的时候它是非常不稳定的,我们采用的最主要的解决方案是采用appends model来代替使用hourly compactions model(注意:这与Hbase的压缩特性无关)。
OpenTSDB对于每一条时间序列数据以指标+标签的形式标记,为了按照小时的来存储这些数据,OpenTSDB需要存储每一条数据的时间增量(从基准时间的偏移),这是一个极为省空间的方式。
在附加模式中,存储一个新的数据点只需要附加到现有的一列上去,然而附加模式需要Hbase去读取现有的数据块,然后把数据点附加到数据块上并将其回写到系统中去,这会产生大量网络传输消耗。
在压缩模式中,它使用一个效率较为低下的结构来存储数据但是它却需要更小的网络带宽,每到一个小时它就会按照更为紧凑、增量化、格式化的数据重写到Hbase存储系统中。这种模式依靠每个小时突然的流量爆发来代替频繁的数据读取与写入,最终实现了流量的降低。
在下面的这张图中你可以看到附加模式和压缩模式下网络传输带宽的对比,压缩模式大幅降低了网络带宽。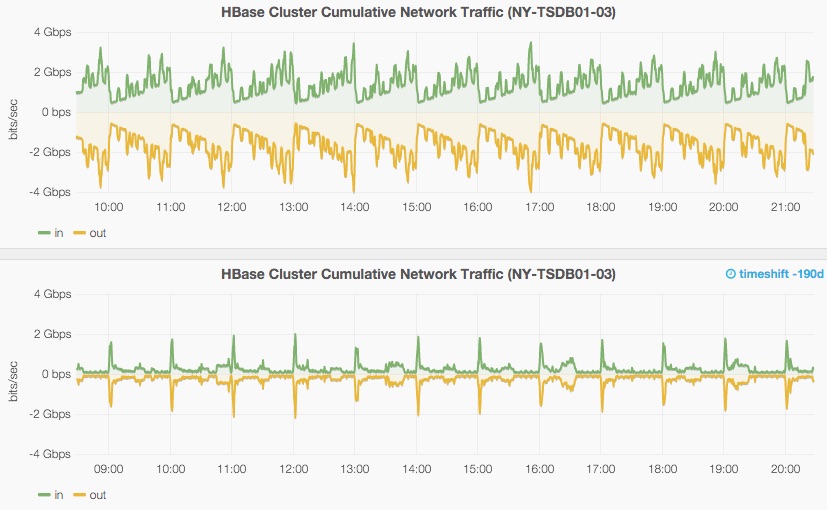
网络带宽的大小出乎我们的意料,主要是考虑到我们写入到OpenTSDB的带宽只有4Mbs(通过HTTP接口以按照gzip压缩的JSON格式写入)。
Zookeeper
我们发现为了稳定性我们需要设置zookeeper的timeouts参数增加到足够大。
zookeeper:
tickTime: 30000
maxSessionTimeout: 600000
Hbase:
zookeeper.session.timeout: 600000
在zookeeper的超时参数较低的情况下,如果某个操作需要较长的时间或者因为Hbase自身的GC时间过长,然后Hbase服务就会干掉他们自己并且停止掉整个集群。
反向序列化、查询速度和持续性
Hbase只有一个引锁,OpenTSDB则是充分利用了整个指标,举个例子,查询一个服务器所有的指标(CPU、内存等)相比于查询所有服务器的单一指标会慢,OpenTSDB使用Hbase的模式例子如下:
00000150E22700000001000001
'----''------''----''----'
metric time tagk tagv
因为指标和时间位于一个列主键的前端,然后因为只有一个主键,在一个指标上你如果拥有更多地标签,那么你需要更多地扫描列来发现你指定的服务器信息,这就降低了查询的速度。
然而,服务器的基本视图是一致的,在这个模式中,他们将拥有多个指标,然后如何去判断这个指标拥有你想要的host,你增加更多地host,那么它的速度也就更慢。
HBase复制
我们遇到过关于Hbase复制的问题,当我们发现问题以及需要将硬盘升级为SSD时,第二Hbase集群需要被重建,在我们最近的复制失败案例中我们发现强制分割能够修复我们在二集群中所遇到的数据分布不平衡的问题(可以通过web的UI界面查看Hbase集群的不平衡分布状态)。
当复制失败时,日志快速增大,日志的消费速度赶不上日志的增长速度。
 由于复制的回滚会消耗大量的磁盘空间,因此我们必须把Hbase的空间指标放在我们监控页面的最顶部。
由于复制的回滚会消耗大量的磁盘空间,因此我们必须把Hbase的空间指标放在我们监控页面的最顶部。
硬件
NY-TSDB0{1,2,3} 每台机器:
| 硬件 | 指标 | 利用率 |
|---|---|---|
| 型号 | Dell R620 | |
| CPU | 2x Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz | ~15% |
| 内存 | 128 GB Ram (8x 16GB Chips) | 34 GB RSS, Rest Used in File Cache |
| 硬盘 | 2 Spinny OS Disks, 8x SSDs in JBOD (INTEL SSDSC2BB480G4) | Avg Read: 1.6 MByte/sec, Avg Write: 57 MByte/sec |
| 网络 | Redundant 10Gigabit | ~500 MBit/sec |
NY-BOSUN02 单机:
| 硬件 | 指标 | 利用率 |
|---|---|---|
| 型号 | Dell R620 | |
| CPU | 2x Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz | ~15% |
| 内存 | 64 GB Ram (4x 16GB Chips) | 20 GB RSS, Rest Used in File Cache |
| 硬盘 | 2 Spinny OS Disks, 8x SSDs in JBOD (INTEL SSDSC2BB480G4) | Avg Read: 1.1MByte/sec, Avg Write: 33 MByte/sec |
| 网络 | Redundant 10Gigabit | ~300 MBit/sec |
参考配置
- opentsdb.conf
- tsdbrelay CLI options (In NY)
- haproxy config (In NY)
- Cloudera HBase Non-Defaults
- Cloudera HDFS Non-Defaults
- Cloudera Zookeeper Non-Defaults
部署
我们使用TeamCity这个工具来作为我们的命令框架,我们使用它来构建scollector、tsdbrelay、Bosun的直接安装包,并且将相关的配置打包到产品中去。TeamCity将每个配置称作为一个"build"。 scollector和tsdbrelay (Linux版本):我们制作了RPM包,
备份
在我们的架构中有三份数据需要备份:
Bosun的的配置文件
- Bosun的状态信息和元数据
- 时间序列数据
我们将Bosun的配置文件保存在GIT中,这样它就能够实现独立的备份了,我们内存使用Gitlab。我们现在使用Redis作为Bosun的状态信息和元数据的存储数据库,Bosun在没有Redis提供的情况下会使用ledis作为状态信息和元数据存储数据库,我们并未对ledis的备份做开发,我们认为使用ledis是作为小的测试来安装的系统。在Redis的持久化中我们同时使用了RDB和AOF技术:
- RDB允许我们对Redis进行快照处理,这样我们就能够方便的转存Redis数据(对于本地开发来说也是如此)。
- AOF允许我们在重启Redis的时候保证数据不丢失。
备份时间序列数据库,在我们架构中就是OpenTSDB,这是一件让人头疼的事情,Hbase被设计用来存储PB级别的数据,在这样量级的数据下,一个全量的备份环境显的不切实际,于是Hbase本身就没有很好地备份支持(查看这篇关于Hbase备份与灾难恢复的文章,这令我们感到羞耻,因为我们在任何一个系统中都没有拥有PB级别的数据,这样子看来全量备份也许是一种好的选择),因此相对于独立的全量备份而言我们做了以下工作: